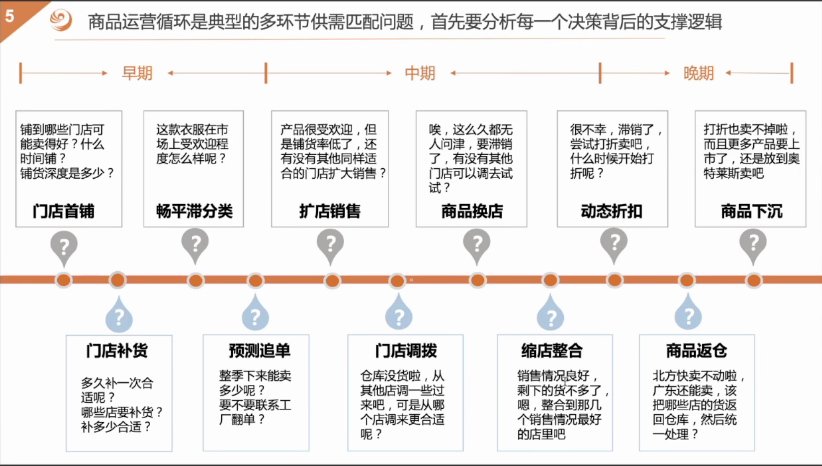
今天从 RL_china 的公众号看到一个JIDI的强化学习平台。包好许多的强化学习的环境和学习资料。感觉挺棒的,收藏起来,好好学习。
RL_china学习
通过参与者数量和智能体数量将强化学习的问题分为:单方但智能体、多方单智能体、单方多智能体和多方多智能体。
机器学习和深度学习基础–陈旭
程序和机器学习的流程上的区别,程序是已知流程求结果。机器学习是1+X=3求X。
选择模型、训练模型、评估模型
eg:回归和分类
博弈、策略和均衡–张海峰
正则。。博弈矩阵 零和博弈、合作博弈、协同博弈、纳什均衡 社会困境(囚徒困境) 纯策略和混合策略
扩展式博弈和不完美信息 (回合) 轮流做选择 博弈树、不完美边和叶子节点(收益)
马尔科夫博弈 –可重复 理性智能体,最大化收益 行为策略(空间远小于混合策略)
贝叶斯博弈和非完全信息 动态贝叶斯博弈
解决方案 占优策略Best response 帕累托最优、 纳什均衡、两人混合博弈中的纳什均衡是一定存在的。
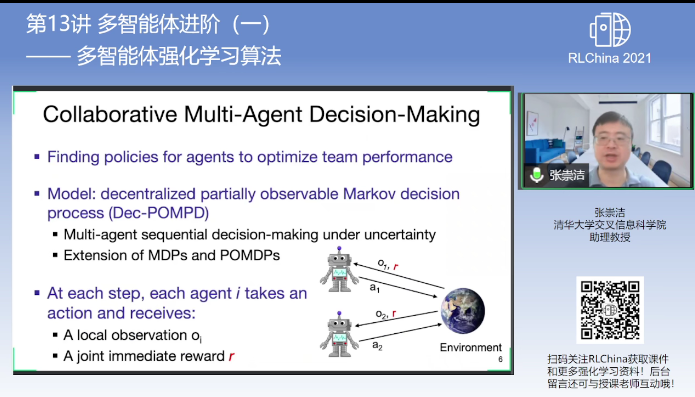
[RLChina 2021]第13课 多智能体进阶(一) 张崇洁
合作多智能体——-Dec-POMDP
 Dec-POMDP is NEXP
Dec-POMDP is NEXP
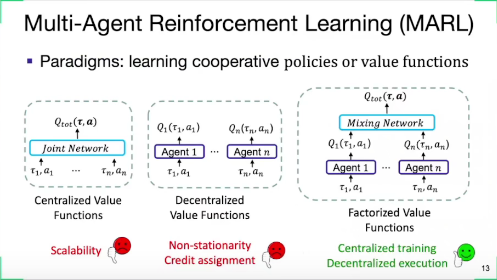
 MARL Challenges
MARL Challenges
- Scalability
- Credit Assignment
- Uncertainty
- Heterogeneity 异质性
- Exploration

Paradigms:
Summary:

Future:
基于模型的MARL
[RLChina 2021]第13课 多智能体前沿(一) 吴翼—捉迷藏游戏策略和开放问题
Hidden seek RPG 奖励随机化—>Fine tune 寻找各种不同的策略 合作-不合作 –Monster-Hunt 离散 共同抓住才算抓住(类似IGSAIL) –Agar.io 球球大作战2人
[RLChina 2021]创业日 创始人专场
俞扬 决策算法—南栖仙策
offline RL ——-> 数据驱动、0试错、少交互
工控、汽车研发、
王一君-供应链 览众数据CEO