
ChatGpt近期很火,也引起了我的兴趣。和聂欣雨交流了一下,在B站上找到了李沐的视屏,另外结合李宏毅的教学视屏进行了学习
Chat Generated Per-trained Transformer 预训练的生成式Transformer聊天模型
 https://img-blog.csdnimg.cn/img_convert/26f55573ebf0d308871491d66d1fdca3.png
https://img-blog.csdnimg.cn/img_convert/26f55573ebf0d308871491d66d1fdca3.png
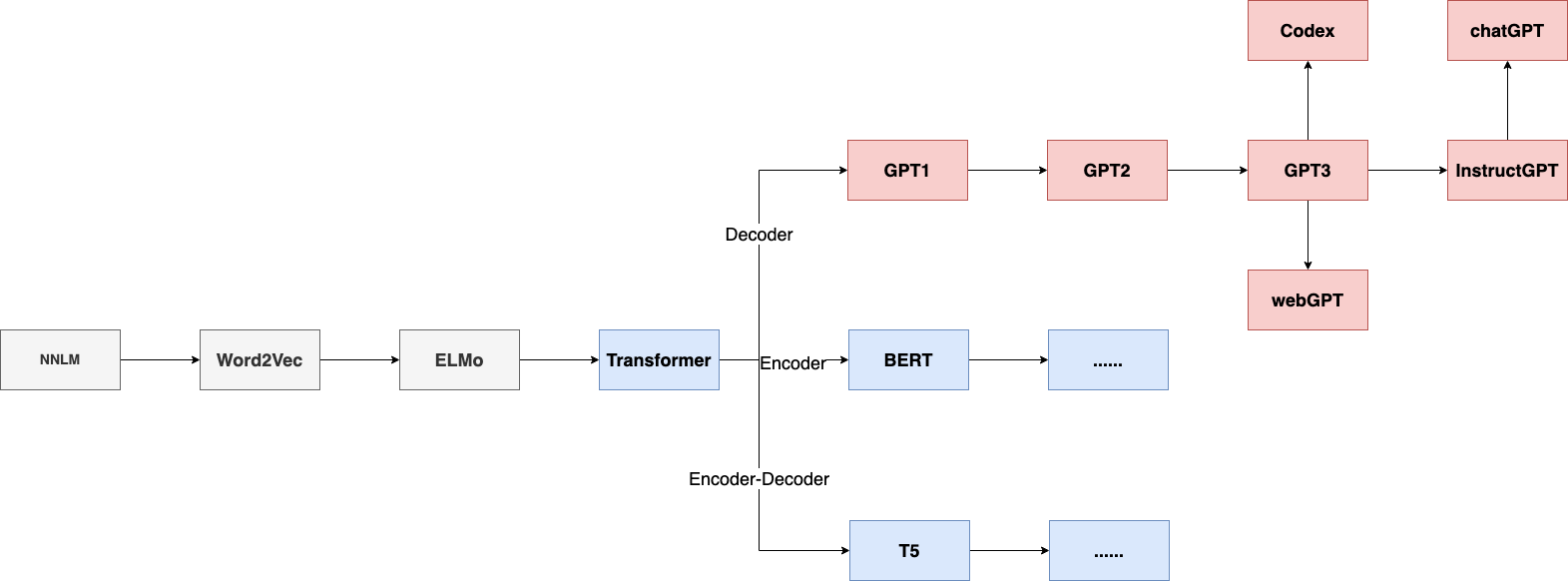
GPT(2018,1.17亿参数)只使用了Transformer解码器并在下游任务上进行微调
GPT2(2019,15亿参数)只使用了Transformer解码器不进行微调;利用上下文进行学习,模型和训练集都更大了;直接在下有任务上使用,测试模型的泛化能力
GPT3(2020,1750亿参数)在GPT2的基础上模型和数据集也都更大了
instructGpt(ChatGpt)使用了人类更喜欢的数据去训练(align对齐);引入了强化学习(PPO算法),将人工标注变为人工打分,可以引导模型学会人类的偏好而不是行为;使用GPT3的架构将最后一层拉平,使用有监督学习来学习奖励函数(能够将好的样本和坏的样本分数拉大)
 https://img-blog.csdnimg.cn/a959430734024d20a916bd56913f3f80.png
https://img-blog.csdnimg.cn/a959430734024d20a916bd56913f3f80.png
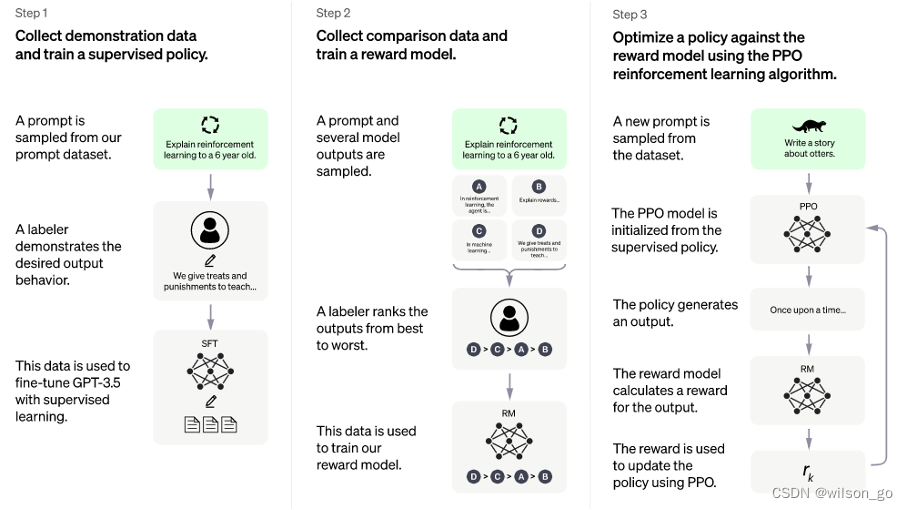
第一步:微调GPT3.5模型。让GPT 3.5在对话场景初步具备理解人类的的意图,从用户的prompt集合中采样,人工标注prompt对应的答案,然后将标注好的prompt和对应的答案去Fine-tune GPT3.5,经过微调的模型具备了一定理解人类意图的能力。
第二步:训练回报模型。第一步微调的模型显然不够好,至少他不知道自己答的好不好,这一步通过人工标注数据训练一个回报模型,让回报模型来帮助评估回答的好不好。具体做法是采样用户提交的prompt,先通过第一步微调的模型生成n个不同的答案,比如A、B、C、D。接下来人工对A、B、C、D按照相关性、有害性等标准标准并进行综合打分。有了这个人工标准数据,采取pair-wise 损失函数来训练回报模型RM。这一步实现了模型判别答案的好坏。
第三步:强化学习来增强微调模型。使用第一步微调GPT3.5模型初始化PPO模型,采样一批和前面用户提交prompt不同的集合,使用PPO模型生成答案,使用第二步回报模型对答案打分。通过产生的策略梯度去更新PPO模型。这一步利用强化学习来鼓励PPO模型生成更符合RM模型判别高质量的答案。
通过第二和第三步的迭代训练并相互促进,使得PPO模型能力越来越强。
人类反馈强化学习
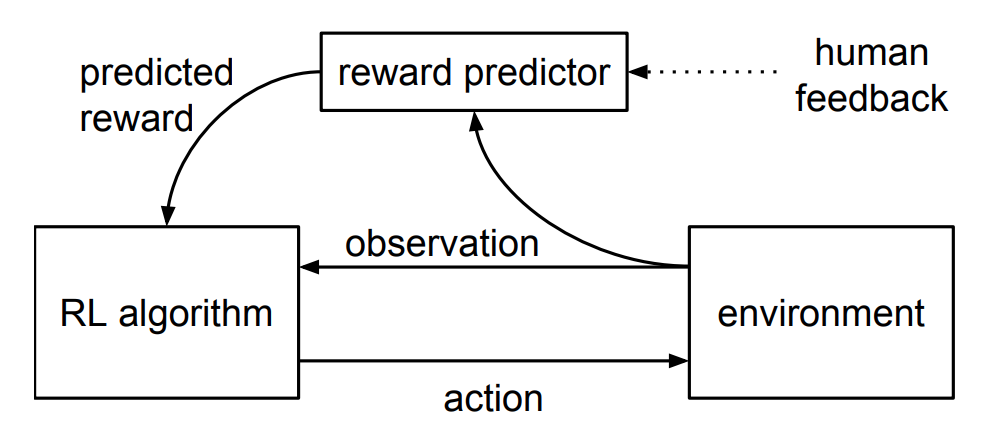
人类反馈强化学习(RLHF)是DeepMind早期提出的,使用少量的人类反馈来解决现代RL任务。RLHF的思想在很多工作中都有体现,例如OpenAI的webGPT、DeepMind中Sparrow等都通过人类的反馈进一步提升大模型的效果。
RLHF整个训练过程如下图所示:
 https://img-blog.csdnimg.cn/img_convert/22c0063c1a0c05b19d9cb667b12052db.png
https://img-blog.csdnimg.cn/img_convert/22c0063c1a0c05b19d9cb667b12052db.png
通过人的反馈数据,学习一个最能解释人类判断的奖励模型Reward Model,然后使用RL来学习如何实现目标。随着人类继续提供模型无法判断时候的反馈,实现了进一步完善它对目标的理解。智能体Agent从人类反馈中学习最终在许多环境中有时甚至是超过人类的表现。
其实就是通过人类反馈来学习一个奖励函数,通过学习的方式使模型达到
-
实际上GPT是在做文字接龙的题
-
GPT是根据提供的一串文字序列预测序列的下一字是什么
-
这个序列可以很长,所以他可以将整个对话当做一个序列作为输入。所以看起来像是模型能够记住前面的输入。
需要学习的知识:
- transformer —> bert
- Beam Search 集束搜索
- GAN —> VAE —> Diffusion

感悟
神经网络是模拟人脑中神经元的链接方式(全连接、RNN、Lstm)创造的,而深度神经网络的出现又极大的扩展了传统神经网络的规模,在图像处理的问题上也证明了通过增大神经网络的规模可以达到更好的结果(ImageNet:AlexNet 、ResNet 、DenseNet)。虽然我们现在还无法解释其内部的运行原理,但已有的研究已经充分证明了大规模神经网络所具备的巨大潜力。
反向传播的技巧给神经网络提供了一种有效的更新方式,使得网络可以学习,可以向着优化目标逐步靠近。而结合强化学习强大的与环境交互的能力,使得神经网络可以持续的获得新的训练样本进行训练,这就相当于为神经网络提供了一种持续的学习的能力。而规模巨大的深度神经网络所拥有的可学习的参数可以是人脑中神经元个数的数百万倍,如果可以这样持续的不受约束的训练下去,其可以达到的智能水平将是十分值得期待的。
深度神经网络是否可以产生自主意识?意识是什么?如果把意识看做是一种处理问题的偏好,那么模型的意识应该就是来自于为模型提供的标签数据,来自于模型训练者们提供的知识之中蕴含的逻辑关系。所以如果这种提供的样本过于片面,就容易产生不被人们接受的逻辑结果,比如:保护人类==圈养人类。或许只有样本的数量足够巨大,才可以减小这种偏差。相信这也将会是科学家门未来的研究方向。